
4 minutes
Oct 10, 2024

‘Beyond Classification: Financial Reasoning in State-of-the-Art Language Models’ 논문을 기반으로 언어모델의 금융 도메인 추론 능력 분석에 관한 내용을 다루고 있습니다. 해당 논문은 FinNLP @ IJCAI2023 학회에 게재되었습니다.
이 시리즈는 원라인에이아이 AI에서 발표한 논문을 리뷰합니다. 논문과 관련해서 궁금한 내용이 있다면 원라인에이아이 AI팀에게 문의주시기 바랍니다.
LLM의 등장과 금융 추론에서의 활용
2022년 겨울, OpenAI의 ChatGPT 등장은 말 그대로 세계를 뒤흔들어 놓았습니다. 사람들은 ChatGPT의 엄청난 성능과 활용 가능성에 열광하기 시작했고, 이러한 열기는 Meta AI의 Llama를 포함한 여러 오픈소스 대규모 언어 모델(LLM)의 등장으로 이어졌습니다. 이로 인해 적은 자원으로도 누구나 LLM을 사용할 수 있게 되었습니다.
오픈소스 LLM의 등장으로 인해 LLM은 법률 및 의학 등 다양한 분야에 활용되기 시작했습니다. 그러나 이에 반해 금융 도메인에서의 활용은 상대적으로 미비했습니다. "Beyond Classification: Financial Reasoning in State-of-the-Art Language Models" 논문은 이러한 문제점을 논의하면서, 최신 LLM이 금융 도메인에서 어떻게 활용될 수 있는지, 특히 투자 의사결정에서 중요한 '금융 추론'에 대한 가이드라인을 제시했습니다. 해당 논문은 금융 도메인에서의 LLM 활용 및 분석의 공로를 인정받아 FinNLP @ IJCAI2023 학회에 게재되었습니다.
Introduction
논문의 배경
기존의 금융 자연어 처리 연구는 주로 토큰 분류 또는 시퀀스 분류와 같은 단순한 작업에 집중되어 있고, 언어 모델을 활용한 복잡한 금융 추론 연구는 거의 이루어지지 않았습니다. 이에 따라 논문에서는 LLM이 금융 분야에서 논리적으로 일관된 투자 의견을 생성할 수 있는가에 대한 답을 찾고자 했습니다.
논문의 목표
논문에서는 금융 도메인에서 LLM의 복잡한 추론 작업 수행 능력을 탐구하기 위해, 투자 의견 생성(Financial Investment Opinion Generation, FIOG)이라는 새로운 태스크를 설정했습니다. 이 태스크는 모델이 투자 결정을 내리는 데 필요한 논리적이고 설득력 있는 의견을 생성하는 것이 핵심입니다.
FIOG를 활용하여 여러 GPT 계열 모델들에 대해 다양한 실험을 진행했고, 그 결과 모델 크기, In-Context Question Answering, Instruction-Tuning 등 다양한 요인이 LLM의 금융 추론 능력에 영향을 준다는 사실을 발견했습니다. 또한, 합성 금융 추론 데이터셋 sFIOG(Synthetic-Financial Investment Opinion Generation)와 해당 데이터셋의 생성 방법을 함께 제안했습니다.
FIOG(Financial Investment Opinion Generation)
논문에서 제안된 핵심 태스크인 금융 투자 의견 생성(FIOG) 태스크는 금융 관련 데이터를 활용하여 인공지능이 투자 의견을 생성하는 작업입니다. FIOG는 모델에게 문제 해결에 필요한 필수적인 정보를 입력으로 주는데, 이때 두 가지 주요 입력 유형이 있습니다: 전체 텍스트 입력 & 질문-답변(Q&A) 입력
1) 전체 텍스트 입력
이 방식에서는 LLM에 완전한 텍스트 정보가 주어집니다. 예를 들어 투자 보고서의 요약이나 관련 자료들이 제공됩니다. 이로 인해 모델은 주어진 모든 정보를 바탕으로 투자 의견을 생성하게 됩니다. 간단히 말하면, 모든 배경 정보와 데이터를 포함한 상태에서 모델이 스스로 결론을 도출하도록 유도하는 것입니다.
2) 질문-답변(Q&A) 입력
Q&A 방식은 모델에 질문과 그에 대한 답변 쌍이 제공됩니다. 이는 모델이 구체적인 질문에 대한 답을 바탕으로 투자 의견을 생성하도록 유도하는 방식입니다. Q&A 방식은 모델이 불필요한 정보에 혼란을 겪지 않고, 꼭 필요한 데이터에만 집중할 수 있도록 도와줍니다. 즉, 정보를 더 체계적이고 통제된 방식으로 제공하는 셈입니다.
Dataset Creation
데이터의 다양성 보장
논문에서는 향후 금융 추론 연구를 위해 합성 금융 투자 의견 데이터셋인 Synthetic-Financial Investment Opinion Generation(sFIOG)과 해당 데이터셋의 제작 방식을 공개했습니다. 이 데이터셋의 질문은 전문가가 중요하다고 판단한 정보에 중점을 두어 만들어졌습니다. 이는 사람 중심의 질의응답을 바탕으로 보다 다양한 측면에서, 풍부한 금융 추론 능력을 개발하는 데 기여할 수 있도록 만들어졌습니다. sFIOG 데이터셋의 생성 프로세스는 다음과 같습니다:
전문가가 작성한 애널리스트 보고서 수집: J.P Morgan, Truist Financial Corp, Oppenheimer & Co. 같은 다양한 소스로부터 1,087개의 애널리스트 보고서를 수집. 이 보고서들은 미국 주식 시장의 752개 기업을 다루고 있음.
전문가 작성 투자 논지 집합 구성: 보고서에서 '투자 논지(Investment Thesis)'와 '관련 리스크' 섹션을 추출해 전문가 작성 투자 논지를 구성 → 1,807개의 투자 논지
Full-Text 타입 입력 구성: 각 애널리스트 보고서의 초록을 수집해 Full-Text 형식의 입력 데이터를 제작 → 4,836개의 투자 논지
Q&A 타입 입력을 위한 질문 생성: GPT-3.5-Turbo API를 이용해 Full-Text 데이터를 바탕으로 중요한 정보를 묻는 질문들을 생성 → 11,802개의 투자 논지
더미 답변 생성: 생성된 질문에 대해 더미 답변을 생성하고, 현실과 너무 동떨어진 답변을 제거하기 위해 인력 검수를 거침
투자 의견 생성: GPT-3.5-Turbo API를 통해 Full-Text 및 Q&A 형식의 입력을 기반으로 투자 의견을 생성
Dataset Overview. (RE)는 재생성된 데이터를 의미함.

데이터 정량 평가 결과
질문 생성 방식의 성능을 평가하기 위해 어휘적 다양성(lexical diversity)과 구문적 다양성(syntactic diversity) 측면에서 두 가지 평가 지표인 Mass와 HD-D를 사용했습니다. 여기에 추가적으로 문장의 다양성을 평가하기 위해 Syntactic Sim이 사용되었습니다. 결과적으로, 제안된 질문 생성 방법은 어휘적, 구문적 다양성이 높은 데이터를 생성하는 것으로 나타났습니다.
HD-D: 텍스트의 어휘적 다양성을 평가하는 지표. 특정 텍스트 내에서 단어들이 얼마나 고르게 분포되어 있는지, 다양한 단어들이 얼마나 사용되는지를 측정. 해당 metric의 score가 높을수록 어휘적 풍부성이 높다는 것을 의미.
Mass: 텍스트의 정보 밀도를 평가하는 지표로, 주로 문장의 구조나 어휘의 선택을 분석하여 텍스트가 얼마나 정보량이 높은지, 혹은 불필요한 정보가 적은지를 판단. 정보가 많이 담겨 있으면 높은 점수를 받습니다. 해당 metric의 score가 높을수록 어휘적 풍부성이 낮다는 것을 의미.
Syntactic Sim: 문법적인 구조가 얼마나 비슷한지 측정하는 지표. 두 개의 텍스트가 있을 때 그 텍스트들이 문법적으로 얼마나 유사한지 비교. 구조가 유사하면 높은 점수를 받음.
few-shot generation과 논문에서 제안된 방법(Step 4)의 퀄리티 평가 결과

In-Context Question Answering
논문에서 제안된 In-Context Question Answering은 기존의 ‘In-Context Learning’ 방식에서 벗어나, 질문과 답변 쌍을 활용하여 더 정확한 맥락 기반 생성 결과를 얻는 방법입니다.
In-Context Learning의 한계
일반적으로 언어 모델들은 학습 과정에서 거대한 양의 데이터를 바탕으로 다양한 정보를 암기하게 되며, 이후 학습된 지식을 바탕으로 새로운 데이터를 처리합니다. 하지만 이 과정에서 현실과 일치하지 않거나, 시대에 뒤떨어진 정보를 생성하는 현상, 즉 hallucination 문제가 발생할 수 있습니다. 특히, 금융 분야처럼 시시각각 변화하는 정보가
In-Context Question Answering의 장점
논문에서는 이러한 문제를 해결하기 위해 In-Context Question Answering 방식을 제안했습니다. 이 방식은 기존의 전체 텍스트를 맥락으로 제공하는 대신, 모델이 학습할 때 질문과 답변 쌍을 입력으로 제공하여 더 명확하고 통제된 결과를 도출하도록 유도합니다. 실험 결과, 이 방식은 기존의 방법에 비해 다음과 같은 이점을 가지고 있다는 것이 확인되었습니다:
의도치 않은 맥락 생성 비율 감소: 예를 들어, 팬데믹 이후 시점에서의 투자 의견을 생성할 때, 기존 방식으로는 약 11.12%가 팬데믹 관련 내용을 불필요하게 포함한 반면, In-Context Question Answering 방식에서는 단 1.63%만이 부적절한 경향을 보였습니다. 이는 질문-답변 형식이 모델로 하여금 주어진 정보에 집중하게 만들고, 불필요한 텍스트로부터 주의를 분산시키지 않기 때문입니다.
인간 평가자의 긍정적 선호도: 1,000개의 샘플을 기반으로 한 실험에서, 인간 평가자들은 약 61.2%의 경우에 이 방식으로 생성된 의견이 투자에 가장 도움이 된다고 응답했으며, 48%는 이 방식이 논리적으로 가장 일관된 의견을 제시한다고 평가했습니다. 이는 기존의 텍스트 기반 학습 방식보다 더 높은 신뢰성과 정확성을 제공할 수 있음을 시사합니다.
수집된 투자 논지의 퀄리티 평가 결과: 초록색은 전문가 작성 데이터, 파란색은 full-text type, 곤색은 Q&A type. G1 & G2는 Q1 & Q2에 대한 GPT-4 답변. H1 & H2는 Q1 & Q2에 대한 사람 답변.
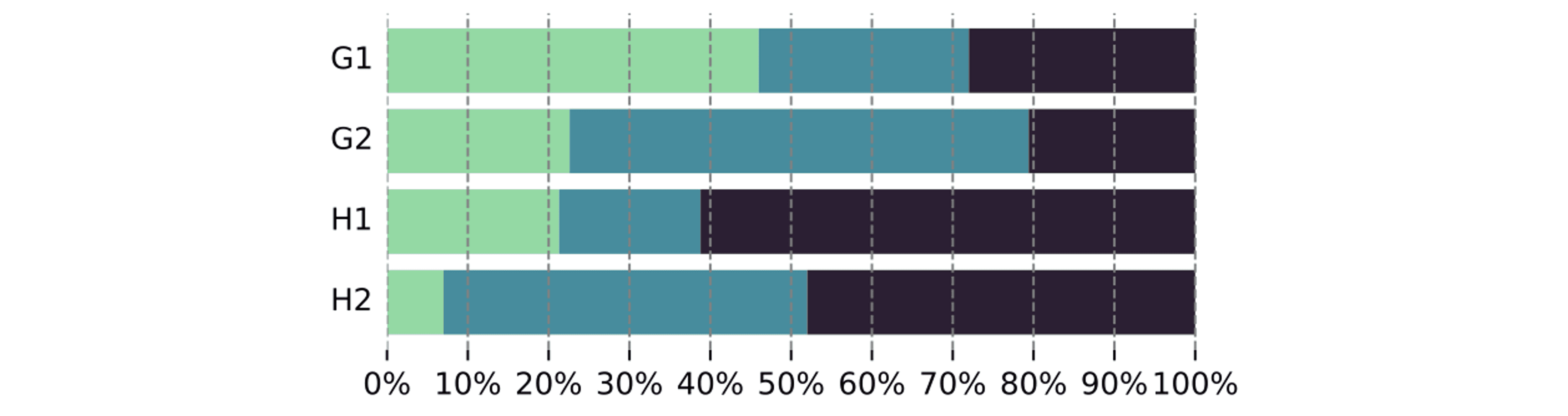
In-Context Question Answering 방식은 기존의 학습 방식에 비해 더 높은 통제성과 정확성을 제공하며, 금융 분야와 같이 변화무쌍한 정보 환경에서 특히 유용한 것으로 나타났습니다. 이를 통해 대형 언어 모델이 보다 신뢰할 수 있는 금융 정보를 제공할 수 있는 가능성을 보여주었으며, 다양한 분야에서도 이 방식이 응용될 수 있는 잠재력을 가지고 있습니다.
Experiments
논문에서는 금융 도메인에서 LLM의 잠재력을 탐구하며, 금융 투자 의견 생성에서의 성능을 다각도로 평가했습니다. 특히, 모델 크기, Instruction-Tuning, 데이터셋 크기에 따른 금융 추론 능력을 집중적으로 분석하였습니다.
Experimental Setup
실험에는 4가지 GPT 계열 모델(2.8B~13B)을 사용되었으며, 각각 Instruction-Tuning을 적용한 경우와 적용하지 않은 경우로 나누어 성능을 비교했습니다. 각 모델은 11,802개의 샘플로 구성된 sFIOG 데이터셋을 3회 반복 학습하였으며, 성능 평가를 위해 ROUGE-L, BERTScore와 같은 자동화된 평가 지표를 사용했습니다.

테스트 데이터셋은 세 가지로 구분되었습니다:
Type#1: 학습 중에 등장한 기업과 질문을 포함하되, 새로운 답변으로 구성된 데이터셋
Type#2: 학습 중 등장한 기업이지만, 새로운 질문-답변 쌍으로 구성된 데이터셋
Type#3: 학습 중에 등장하지 않은 기업과 새로운 질문-답변 쌍으로 구성된 데이터셋
이러한 설정을 통해 모델이 얼마나 새로운 환경에 적응하며, 금융 추론을 일관되게 수행할 수 있는지를 평가했습니다.
1. Model Scale and Financial Reasoning
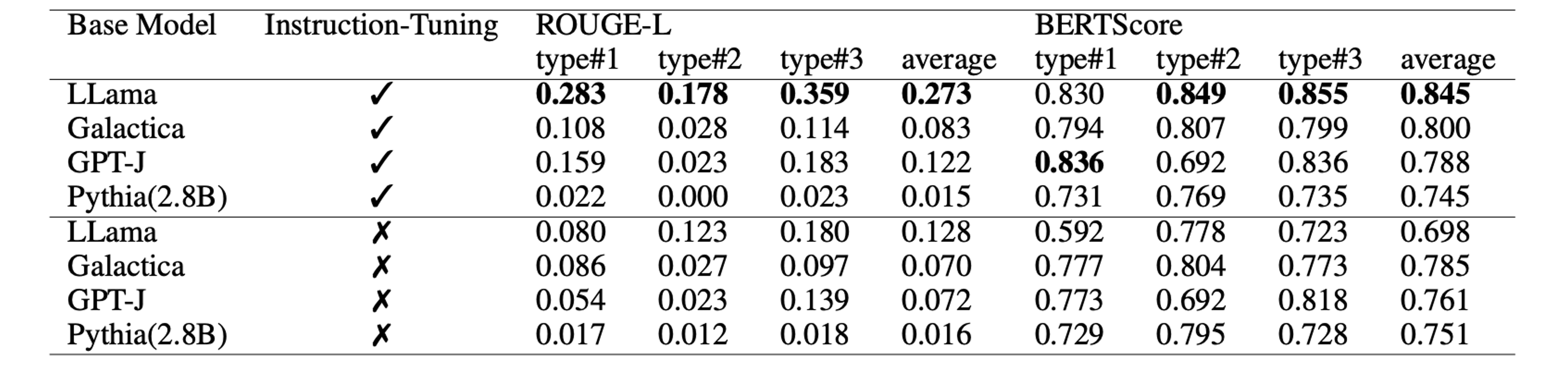
실험 결과, 모델의 금융 추론 능력은 2.8B에서 6B 파라미터 규모 사이에서 명확히 드러나기 시작하며, 모델 크기가 커질수록 그 성능이 꾸준히 향상되었습니다. 특히, 13B 파라미터 규모의 LLama 모델이 가장 뛰어난 성능을 보였으며, 이는 ROUGE-L(0.217)과 BERTScore(0.821) 점수에서 가장 높은 평균치를 기록했습니다. 이러한 성능 향상은 두 가지 요인으로 설명될 수 있습니다:
큰 모델일수록 더 많은 데이터를 학습하여 금융에 대한 지식이 풍부해집니다.
모델의 아키텍처 자체가 더 큰 규모에서 더 나은 추론 능력을 발휘하게 됩니다. 특히, LLama 모델의 경우 학습된 정보들을 더 효과적으로 분석하고 종합하여 일관된 금융 추론을 수행하는 데 유리한 구조를 가지고 있음을 확인할 수 있었습니다.
sFIOG 데이터셋에서 얻어진 LLama, Galactica, GPT-J, Pythia 결과
2. Instruction-Tuning and Financial Reasoning
Instruction-Tuning은 모든 모델의 성능을 향상시키는 데 중요한 역할을 했습니다. 하지만 그 개선 폭은 모델마다 달랐으며, 이는 Instruction-Tuning에 사용된 데이터셋의 차이에 기인할 수 있습니다. 특히 가장 작은 모델인 Pythia(2.8B)는 Instruction-Tuning을 적용하더라도 일관된 금융 추론 능력을 보여주지 못했습니다. 이는 금융 추론 능력이 일정한 모델 크기 이상에서 발현되는 특성임을 시사합니다. 즉, 작은 규모의 모델은 적절한 Instruction-Tuning이 이루어지더라도 복잡한 금융 추론을 처리하는 데 한계가 있음을 알 수 있습니다.
3. Dataset and Financial Reasoning
각 데이터셋 유형별로 모델 성능을 비교한 결과, 새로운 질문-답변 쌍을 처리하는 type#2 데이터셋에서 모델들이 가장 약한 성능을 보였습니다. 학습 중 등장하지 않은 기업을 다루는 type#3 데이터셋이 가장 어려운 과제일 것이라 예상되었지만, 실제로는 익숙한 기업에 대한 새로운 질문을 다루는 것이 더 어려운 과제임이 발견되었습니다. 이는 **비정상적이거나 변화하는 지식(non-stationary knowledge)**이 모델의 일반화 능력에 영향을 미치며, 기존 지식을 새로운 상황에 적응시키는 데 어려움을 겪을 수 있음을 보여줍니다.
추가로, LLama 13B 모델을 다양한 데이터셋 크기와 학습 단계를 기준으로 평가한 결과, 데이터셋 크기와 학습 단계가 성능에 미치는 영향도 확인할 수 있었습니다. LLama는 더 많은 학습 단계를 거칠수록 성능이 개선되었지만, 작은 데이터셋으로 학습한 경우에도 Instruction-Tuned GPT-J 모델보다 우수한 성능을 보였습니다. 이는 모델 크기가 금융 추론을 생성하는 데 중요한 요인임을 나타내며, 데이터셋 크기는 상대적으로 덜 중요할 수 있음을 시사합니다.
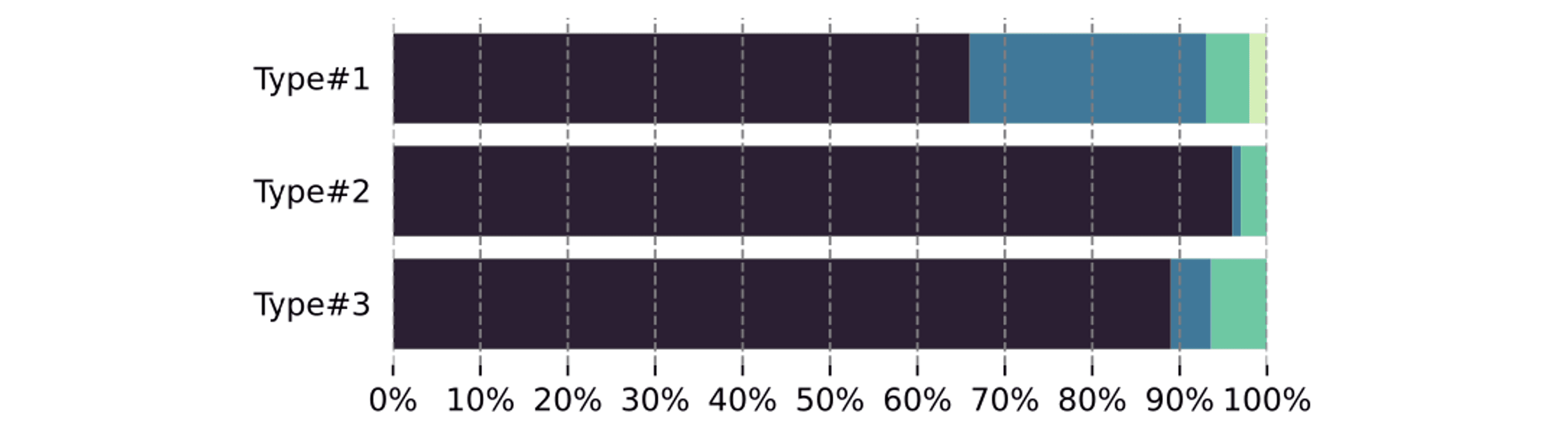
4. Human Preference
최종적으로 인간 평가자들이 각 모델이 생성한 투자 의견을 비교했습니다. 평가자들은 LLama 모델이 가장 일관성 있고 관련성 높은 내용을 생성한다고 평가했으며, 특히 coherence(일관성), relevance(관련성), fluency(유창성) 면에서 다른 모델들보다 우세하다는 결과가 나왔습니다. 이러한 결과는 앞서 살펴본 자동화된 평가 지표인 ROUGE-L과 BERTScore 에서도 일관되게 나타났습니다.
생성된 샘플에 대한 Human preference. 곤색은 LLama, 초록색은 Galatica, 파란색은 GPT-J, 노란색은 Pythia.
Conclusion
“Beyond Classification: Financial Reasoning in State-of-the-Art Language Models” 논문은 금융 분야에서 언어 모델이 수행할 수 있는 금융 추론 능력을 심층적으로 분석한 최초의 논문으로, 모델 사이즈, In-Context Question Answering, Instruction-tuning의 효과 등을 포함해 다방면으로 모델의 금융 추론 능력을 분석하였습니다.
실험 결과, 모델들은 어느 정도 금융 추론 능력을 가지고 있지만, 언어 모델이 인간 평가자와 동일한 수준의 평가를 수행하지 못하는 한계도 드러났습니다. 이는 언어 모델이 금융 도메인에서 완전히 신뢰할 수 있는 평가 도구로 사용되기에는 아직 부족함이 있음을 시사합니다.
결론적으로, 해당 연구는 금융 추론 분야에서 언어 모델의 가능성을 입증하며, 더 나아가 대형 언어 모델의 금융 도메인 적용 가능성을 넓히는 데 중요한 첫걸음이 되었습니다. 향후 더 큰 규모의 모델과 다양한 데이터셋을 활용한 연구를 통해, 언어 모델이 금융 전문가들의 의사결정 과정에서 중요한 도구로 자리 잡을 수 있기를 기대합니다.