
4 minutes
2025. 4. 24.

다양한 한국어 LLM의 등장
2024년 8월, LG AI Research에서 공개한 한국어-영어 bi-lingual 언어 모델 EXAONE-3.0 이후로 후속 모델인 EXAONE-3.5, 카카오의 kanana, 그리고 네이버의 HyperClovaX Seed까지 다양한 한국어 오픈소스 모델이 등장하였습니다. 해당 모델들은 KMMLU, HAERAE-Bench, CLIcK, KoBEST 등 다양한 한국어 벤치마크에서 뛰어난 성능을 보여주며 한국어 오픈소스 언어 모델 시장의 중요한 모델들로 자리 잡고 있습니다.

현재 가장 많이 사용되는 한국어 벤치마크인 KMMLU의 2년전 첫 공개 당시에는 HyperClova X-Large가 53.4점으로 최고점을 기록했지만, 현재는 불과 3B 규모의 HyperCLOVAX Seed 모델이 48.47점을 기록했습니다. 따라서 다양한 한국어 벤치마크에서 좋은 성능을 보여준 모델들(EXAONE, Kanana, HyperCLOVAX Seed)을 대상으로 LLM의 간단한 평가 방법으로 많이 사용되는 2-digit multiplcation problem, 즉 '구구단 문제'를 통해 모델의 성능을 직접 측정해 보았습니다.
구구단을 외자!
구구단 문제는 1부터 100까지의 곱셈(예: 7x9)을 "\boxed{}" 형식으로 답하도록 요청한 뒤, 총 10,000개 조합의 응답을 정규표현식으로 파싱해 정답 여부(정답=1, 오답=0)를 이진 행렬로 구성하여 분석하였습니다. 해당 결과를 녹색(정답)·적색(오답) 컬러맵의 히트맵으로 시각화하여, 모델이 영어 입력과 한국어 입력에서 각각 어떤 분포로 답을 맞추는지 확인해보았고, 실험에 사용된 모델과 환경은 다음과 같습니다:
모델
Naver: HyperCLOVAX-SEED-Text-Instruct-1.5B (vllm inference 이슈로 인해 1.5B 사용)
Kakao: kanana-nano-2.1b-instruct
LG AI Research: EXAONE-3.5-2.4B-Instruct
Alibaba: Qwen2.5-1.5B-Instruct
실험 환경
temperature: 0.0
max_tokens: [10, 20, 40, 80]
vllm==0.8.4
code: Link
실험 결과
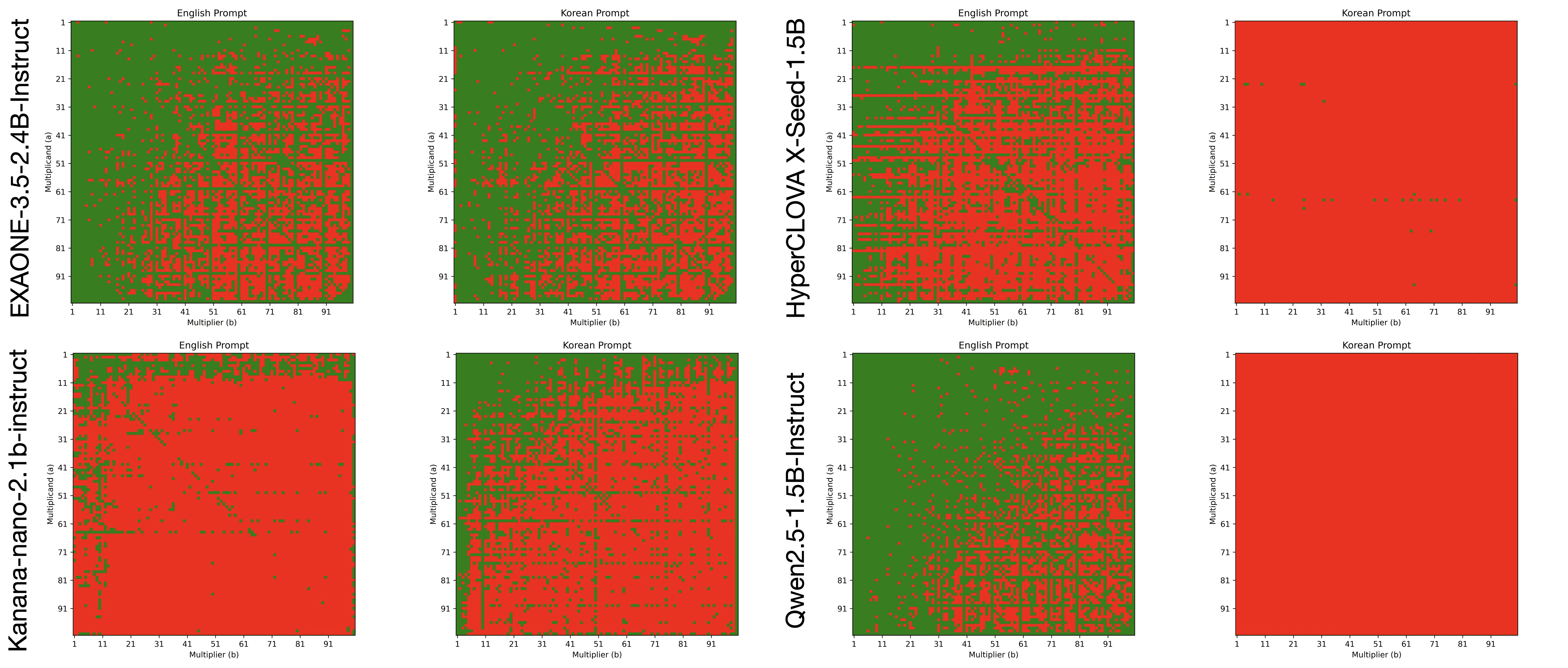
실험 결과는 다음의 히트맵과 표와 같습니다. 히트맵에서 확인할 수 있듯이 대부분의 모델이 작은 숫자의 곱셈에서는 어느 정도 정확한 계산 결과를 보여주지만, 높은 숫자의 곱셈에서는 점점 성능이 낮아지는 것을 볼 수 있습니다.
'구구단 문제' 결과 (max_tokens=10)
'구구단 문제' 성능 (max_tokens=10)

추가 실험 결과
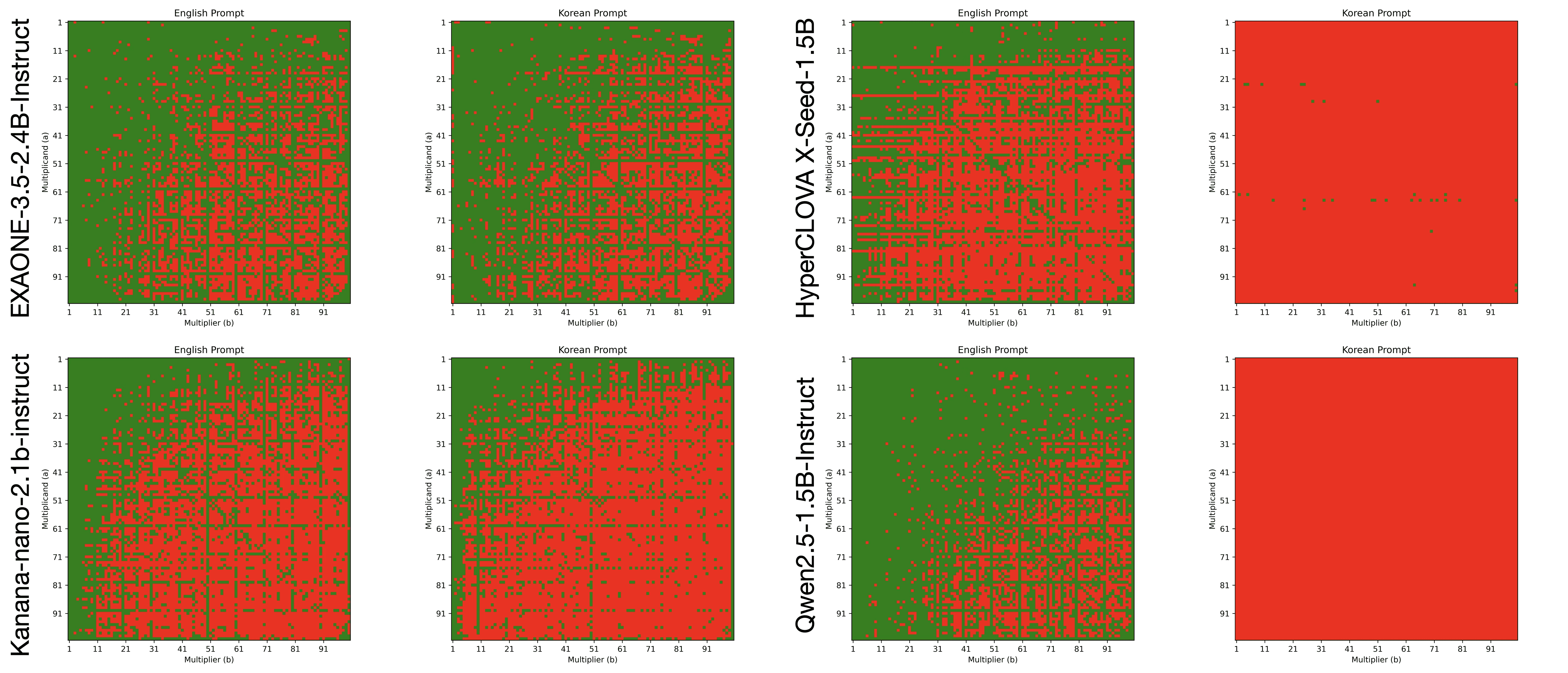
본 실험은 max_tokens를 10으로 설정하여 진행하였지만, 낮은 output token limit으로 인해 발생할 수 있는 답변 잘림 문제 등을 해결하기 위해 20, 40, 80 토큰에 대한 실험도 추가적으로 진행하였습니다.
[max_tokens=20 결과]
[max_tokens=40 결과]

[max_tokens=80 결과]
max_tokens에 따른 성능 변화 분석 (English)

한국어 LLM에 대한 분석
한국어 LLM 각각에 대한 '구구단 문제' 실험 결과 분석은 다음과 같습니다:
HyperCLOVAX Seed: 영어에서는 괜찮은 성능을 보여주지만, 한국어에서는 굉장히 안 좋은 성능을 보여줍니다. (한국어-영어의 성능 차이가 큼)
Kanana: 한국어에서는 괜찮은 성능을 보여주지만, 영어에서는 굉장히 안 좋은 성능을 보여줍니다. (한국어-영어의 성능 차이가 큼)
EXAONE: 영어와 한국어 모두에서 굉장히 robust한 성능을 보여줍니다. (한국어-영어의 성능 차이가 별로 없음)
서로 다른 한국어 LLM은 각각이 상이한 특징을 보였는데, 이를 통해 각 모델의 특징을 조금이나마 확인할 수 있었습니다. 여기에 추가적으로 실험 결과를 통해 다음과 같은 특징들 또한 확인할 수 있었습니다:
특징 1: 모델들이 공통적으로 제곱수(대각행렬)와 10의 자릿수 곱셈에 대해서는 높은 정확도를 보여줍니다.
특징 2: 대각행렬을 기준으로 완전 대칭이 아닌 것으로 보아 똑같은 곱셈이라도 피연산자의 위치에 따라서 성능이 달라지는 것으로 보입니다.
특징 3: Kanana의 경우, max_tokens가 늘어남에 따라 정확도가 크게 오르는 것을 확인할 수 있습니다. 이는 해당 모델이 영어로 답변을 출력할 때, 한국어보다 좀 더 많은 토큰을 뱉음으로써 답변이 잘리는 문제를 해결할 수 있었던 것으로 보입니다.
특징 4: HyperCLOVAX Seed의 경우, 일의 자리수가 '7'인 행과 열에서 오답이 자주 발생하는 것을 확인할 수 있습니다.
마치며..
최근 EXAONE, Kanana, HyperCLOVAX Seed 등 다양한 한국어 오픈소스 LLM이 잇따라 공개되면서, 국내 인공지능 생태계 전반에 큰 활력을 불어넣고 있습니다. 이처럼 한국어에 최적화된 모델들이 지속적으로 등장하고 있다는 사실은, 단순한 기술적 진보를 넘어 한국어 LLM 연구의 새로운 전환점을 예고하는 반가운 흐름입니다.
특히 그동안 영어 중심으로 발전해온 LLM 연구 흐름 속에서, 한국어라는 언어의 고유한 특성과 구조를 깊이 있게 반영한 모델들의 등장은 국내 연구자들에게 더 많은 기회를 제공하고 있습니다. 각 모델들이 저마다의 철학과 기술적 접근을 기반으로 다양한 활용 사례를 만들어내고 있는 만큼, 이러한 흐름이 단발적인 현상에 그치지 않고, 보다 지속적이고 체계적인 연구로 이어져 한국어 LLM 생태계가 더욱 견고해지기를 바랍니다. 또한 저희 원라인에아이에서도 한국어 LLM의 사용성을 평가할 수 있는 다양한 벤치마크와 평가 방법들을 끊임없이 만들어나가겠습니다!