
4 minutes
2025. 4. 10.

KRX 금융 언어 모델 경진대회와 ₩ON 모델 제작 이야기
인공지능의 발전은 모든 산업을 빠르게 변화시키고 있습니다. 그중에서도 금융 분야는 AI 기술이 빠르게 확산되고 있는 대표적인 산업군 중 하나입니다. 이러한 빠른 발전에 발맞춰서 KRX는 금융 특화 언어 모델의 개발과 성능 향상을 촉진하고, 이를 통해 더욱 정확하고 효율적인 금융 정보 분석 및 예측 서비스를 제공하고자 KRX 금융 언어 모델 경진대회를 개최하였습니다.
해당 대회에서 참가자들이 제출한 금융 특화 언어 모델을 평가하기 위해 KRX와 OnelineAI가 공동 개발한 'KRX-Bench'를 이용하였습니다. 참가자들은 각자의 방법론을 활용하여 모델을 학습시키고 제출하면, KRX-Bench에서 제출 모델의 금융 능력을 평가하여 리더보드를구축하는 방식으로 대회가 진행되었습니다. 약 2개월 동안 진행된 경진대회를 통해 기록된 수많은 정보들을 활용하여 강력한 금융 언어 모델을 만들기 위한 다양한 노하우가 담긴 Technical Review와 해당 노하우들을 기반으로 제작된 한국어 금융 언어 모델인 ₩ON에 대해서 자세히 소개하겠습니다.
KRX 금융 언어 모델 경진대회에 대하여..
본 경진대회는 한국 금융 분야에서 최초로 시도된 공개적인 LLM 평가 리더보드 구축 및 모델 평가 경진대회입니다. 약 2개월간 진행된 이번 대회는 233개의 팀이 참가 등록을 완료하였으며, 총 1,119개의 모델이 제출되는 등 놀라운 성과를 기록하며 마무리되었습니다. 또한 참가팀의 절반 이상인 52.5%가 기업 참가자였으며, 그 외에는 모두 학계 관계자인 것으로 보아 금융 LLM 분야가 다양한 도메인으로부터 관심을 받고 있다는 것을 보여주었습니다. 여기에 추가적으로 현재까지도 약 600개 이상의 모델이 HuggingFace를 통해 공개적으로 활용 가능하며, 한국 금융 NLP 연구를 위한 소중한 자산으로 남아있습니다.

경진대회는 예선과 본선, 총 2가지 단계로 나눠서 진행되었으며 각 단계에서는 다음과 같이 서로 다른 방향성으로 진행하였습니다:
예선: MCQA 유형의 비교적 쉬운 질문으로 구성된 5개의 서브셋을 포함하는 벤치마크 평가. (재무회계, 금융시장, 주가 예측, 국내 기업, 금융 에이전트)
본선: MCQA 및 Instruction-Response 유형의 비교적 어려운 질문으로 구성된 3개의 서브셋을 포함하는 벤치마크 평가. (재무회계, 금융시장, 금융 질의응답)
경진대회에 사용된 벤치마크는 다음과 같이 6가지 서브셋에서 총 5,500개 이상의 평가 항목으로 구성되었습니다. 이때 각 서브셋에 대한 자세한 설명은 다음과 같습니다:
재무회계(MCQA): 대학 시험에서 출제된 4지선다형 객관식 문제로 구성되어 있으며, 예선에서는 4개, 본선에서는 8개의 보기로 확장하였습니다. 문제의 난이도를 높이기 위해 임베딩 기반의 유사 문제 혼합과 "위의 보기 중 없음"과 같은 규칙 기반의 보기 교체와 같은 데이터 증강 기법을 사용하였습니다.
금융시장(MCQA): 재무회계 서브셋과 유사한 방식으로 구성되었으며, 주로 한국의 금융 시스템과 관련 법률에 대한 이해를 평가하는 시험 문제를 기반으로 하고 있습니다.
주가 예측(MCQA): 한국 주식 시장의 최신 데이터를 사용하여 OHLCV(시가, 고가, 저가, 종가, 거래량)와 같은 기본 데이터를 무작위로 추출한 후, 기술적 지표(예: 최근 5일, 10일, 15일, 20일, 25일, 30일 동안의 변화율 등)를 계산하여 제공하였습니다. 모델은 주가가 향후 상승할지 하락할지를 이진 분류 문제로 예측해야 하며, 기본적인 모멘텀 또는 평균 회귀 신호 탐지 능력 등을 평가합니다.
국내 기업(MCQA): KRX-Bench를 직접 사용하여 구성하였으며, GPT-4o를 활용하여 한국 상장 기업의 연례 보고서를 바탕으로 자동 생성된 객관식 문제로 이루어져 있습니다. 이 서브셋은 기업의 제품 제공, 재무 정책, 사업 전략과 같은 특정 분야의 지식을 평가합니다.
금융 에이전트(MCQA): 실제 금융 데이터를 기반으로 자동화된 금융 에이전트로 기능할 수 있는 능력을 평가합니다. 모델에게 CSV 파일과 특정 정보를 추출하거나 데이터를 처리하는 코드 작업 지시를 제공하고, 모델은 여러 변형된 출력 옵션 중에서 올바른 답안을 선택해야 합니다.
금융 질의응답(Instruction-Response): 객관식 평가의 한계를 보완하기 위해, 실제 응용 시나리오를 더 잘 반영할 수 있도록 보다 도전적인 100개의 Instruction-Response 프롬프트로 구성된 서브셋입니다. 법적 추론을 포함한 KRX-Bench의 일부, HRM8K의 고급 수학 문제, 대학원 수준의 금융공학 및 계량경제학 시험 문제에서 추출한 질문으로 구성되었으며, 정답 평가를 위해 GPT-4o를 활용한 LLM-as-a-Judge 평가 방식을 사용하였습니다.

경진대회 결과 분석
대회에 참가한 모든 팀들의 노하우가 담긴 결과를 토대로 다음과 같이 데이터셋 구성, 상위 모델 방법론 분석 등을 진행하였습니다.
데이터 수집 분석
이번 경진대회에서는 참가팀들이 라이선스 문제가 없는 금융 관련 콘텐츠를 중점적으로 수집했습니다. 가장 많이 활용된 출처는 정부(go.kr) 및 비영리 기관(or.kr)의 도메인이었으며, 주요 출처로는 한국거래소(KRX), 금융위원회(FSC), 한국은행(BOK) 등이 있었습니다. 참가자들이 중점적으로 수집한 데이터 소스는 다음의 표와 같습니다.

예선 상위 모델 분석
예선 상위 10개 팀은 모두 Qwen2.5-7B-Instruct 모델을 기반으로 SFT를 적용하여 높은 성과를 기록했습니다. 특히, 국내 기업 카테고리에서는 0.51에서 0.94로 가장 큰 성능 개선이 이루어졌지만, 재무회계, 금융 시장 카테고리에서는 상대적으로 미미한 성과 향상이 관찰되었습니다.
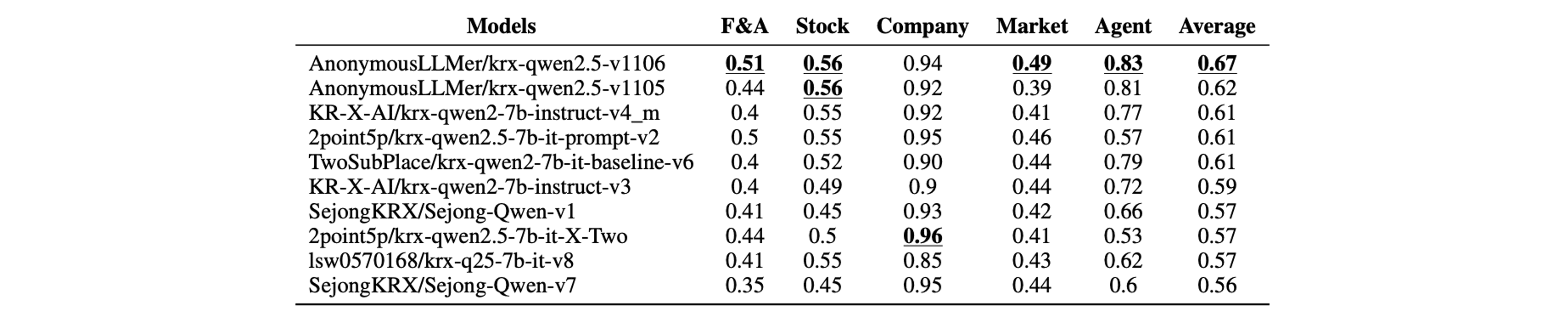
또한 대회 진행이 흐름에 따라 전반적으로 모델들이 성능이 우상향을 보여주는 것 또한 볼 수 있었습니다.

본선 상위 모델 분석
본선에서는 더 복잡하고 다단계적인 훈련 전략이 사용되었습니다. 예를 들어 Shibainu 팀은 난이도 기반 커리큘럼 학습을 적용했고, 추가로 DPO(Direct Preference Optimization)를 활용해 모델의 응답 품질을 정교하게 개선했습니다. Hi-Q와 overfit-brothers 팀 역시 DPO와 KTO 같은 고급 미세조정 방식을 사용했습니다. 특히 Hi-Q 팀의 분석 결과, 지속적 사전학습인 Continual Pre-training(CPT)과 SFT을 결합한 경우가 단순 SFT보다 약 2.7점 더 높은 성과를 보였으며, 이는 금융 특화 모델의 성능을 높이는데 CPT의 유효성을 시사합니다.

종합 평가 및 시사점
경진대회의 결과는 금융 분야에서 우수한 성능을 보이는 한국어 특화 언어 모델 개발에 있어 효과적인 데이터 수집과 복합적인 미세조정 전략이 중요함을 강조했습니다. 데이터의 품질 관리와 라이선스 문제 회피가 중요하며, 이러한 과정을 통해 고품질의 학습 데이터를 확보할 수 있었습니다. 또한, 복잡한 모델 학습 전략이 어려운 현실적인 금융 문제를 잘 해결하는 데 효과적이라는 사실이 입증되었습니다. 이는 앞으로의 금융 특화 모델 개발 및 평가 과정에서 중요한 지침으로 활용될 수 있을 것으로 기대됩니다.
오픈 한국어 금융 언어 모델: ₩ON
모델 학습 데이터셋 제작
₩ON 모델의 학습은 앞서 설명한 '경진대회 결과 분석 - 데이터 수집 분석'의 내용을 기반으로 대회 기간 동안 수집된 약 20만 개의 데이터 중 중복 제거와 품질 검사를 통해 최종 선별된 86,000여 개의 고품질 한국어 금융 데이터를 기반으로 진행하였습니다. 수집된 raw data에 대해서는 GPT-4o 및 Qwen2.5-72B-Instruct 모델을 활용하여 객관식(MCQA) 또는 지시문-응답(Instruction-Response) 형식으로 변환하였습니다. 마지막으로 이렇게 제작된 데이터셋에 대해 추가적인 필터링을 진행하여 최종 데이터셋을 구축하였습니다. 자세한 데이터 수집 및 처리 과정은 다음과 같습니다:
데이터 수집: 경진대회 중 HuggingFace에 제출된 200,000개 이상의 데이터 중 MinHash 알고리즘과 정규식 필터링을 통해 선별된 86,000여 개의 Instruction 데이터셋을 구축
추론 응답: DeepSeek-R1 모델을 사용하여 생성된 응답과 함께 영어 및 한국어 온라인 자료에서 수집한 Prompt-Response 쌍으로 보완
검증: GPT-4o를 LLM-as-a-Judge로 활용한 검증 프로세스 및 자동 품질 검사를 통해 데이터의 무결성과 정확성을 강화
해당 데이터셋에 대한 보다 자세한 내용은 HuggingFace에 공개되어 있는 Won-Instruct 데이터셋을 참고해주시길 바랍니다.
모델 학습 방법론
₩ON 모델 학습에는 최신 연구 흐름과 경진대회 우승 팀들이 사용한 학습 전략에서 영감을 받아 2단계 학습 과정을 적용하였습니다:
Supervised Fine-Tuning (SFT): 금융 추론 작업과 관련된 모델의 초기 행동을 조정하는데 초점을 맞췄으며, DeepSeek-R1 모델로 생성한 상세한 응답과 세심하게 선정된 프롬프트를 사용하여 학습하였습니다.
Direct Preference Optimization (DPO): SFT 진행 후, 모델의 과도한 생각 과정 또는 일부 질문에 대한 잘못된 해석과 같은 원치 않는 행동을 완화하기 위해 DPO를 활용하여 모델을 추가 학습하였습니다. 이때 모델의 출력과 DeepSeek-R1의 출력을 비교함으로써 선호도 데이터를 제작하였습니다.
이와 같은 과정을 통해 학습된 ₩ON 모델은 다음과 같은 특징을 가지고 있습니다:
Base Model: Qwen2.5-Math-7B-Instruct
Language: Korean, English
Model Size: 7B
Inference:
₩ON은 두 단계의 구조적 추론 과정을 거칩니다.
Thinking Stage: 모델은 `<think>` 및 `</think>` 태그 내에서 자신의 추론 과정을 명시적으로 보여줍니다. 이는 투명성을 높이고, 사용자들이 ₩ON의 결론 도출 방식을 이해하는 데 도움을 줍니다.
Solution Stage: 추론 진행 후, 모델은 결론을 `<solution>` 및 `</solution>` 태그 내에서 명확하고 간결하게 요약하여 제시합니다.
모델 성능 평가 및 분석
₩ON 모델을 본선에 사용된 벤치마크로 평가한 결과 다음의 표와 같은 결과가 나왔습니다. ₩ON 모델은 재무회계 및 금융 질의응답 서브셋에서 특히 우수한 성능을 보이고, 이에 반해 금융시장 서브셋에서는 조금 약한 모습을 보여줬습니다. 이는 모델이 학습 과정에서 추론 위주의 데이터에 더 초점을 맞췄기 때문에 수학적, 논리적 추론 능력을 요구하는 복잡한 질문들에 대해 강력한 성능을 보이는 반면, 사실적이고 도메인 특화된 지식을 요구하는 질문들에 대해서는 상대적으로 약한 성능을 보이는 것으로 해석할 수 있습니다.

이러한 결과를 통해 추론 위주의 학습 방법이 특정 금융 문제 해결에는 효과적인 한편, 향후 금융 도메인 지식 및 사실 기반 데이터를 균형 있게 추가 학습시키는 것이 성능의 종합적 개선을 위해 필수적이라는 것을 보여줍니다.
마치며..
KRX 금융 언어 모델 경진대회는 금융 분야에서의 한국어 LLM 개발과 평가의 새로운 가능성을 확인시켜준 중요한 계기가 되었습니다. 특히, 이 과정에서 축적된 데이터와 학습 노하우는 앞으로의 금융 특화 모델 연구에 값진 토대가 될 것으로 기대됩니다. ₩ON 모델의 사례는 금융 AI의 실무적 활용 가능성을 보여주는 동시에, 향후 더 고도화된 금융 지식과 추론 역량을 갖춘 모델이 지속적으로 개발되어야 한다는 과제를 남겼습니다. 앞으로도 이러한 도전이 지속되어 한국 금융 시장이 글로벌 AI 경쟁력을 확보하는 데 기여할 수 있기를 바랍니다.
References
🖥️ Won-Reasoning: https://huggingface.co/KRX-Data/WON-Reasoning
💾 Won-Instruct: https://huggingface.co/datasets/KRX-Data/Won-Instruct
📝 Won: Establishing Best Practices for Korean Financial NLP: https://arxiv.org/abs/2503.17963
📝 KRX Technical Review: Coming Soon!